
Безопасность микросервисов и API
Честно говоря, тема безопасности API и микросервисов сейчас — это тот случай, когда теория от практики отличается раз так в пять. Я сам не раз попадал в ситуации, когда вроде бы всё настроено по OWASP, все галочки проставлены, а потом на нагрузочном тестировании или, что еще хуже, при реальной атаке что-то шло не по плану. В этой статье я хочу поделиться именно практическим опытом, а не просто пересказать NIST SP 800-228 или OWASP API Security Top 10 2023.
Статья будет полезна DevOps-инженерам, архитекторам и всем, кто имеет дело с распределенными системами. Мы разберем, как выстраивать защиту так, чтобы не тормозить разработку, но и не превращать инфраструктуру в решето. Особое внимание уделим нюансам российского рынка: 152-ФЗ никто не отменял, и регуляторы становятся всё внимательнее к API.
Контроль доступа в микросервисах: от теории к практике
RBAC и ABAC — вечная дилемма
По моему опыту, большинство команд начинают с ролевой модели (RBAC). Это логично: проще назначить роль «администратор» и дать ей все права. Но в микросервисной архитектуре это быстро превращается в ад. Представьте: у вас 50 сервисов, в каждом своя логика ролей. И тут приходит задача разграничить доступ так, чтобы менеджер видел отчеты по продажам, но не видел зарплату сотрудников. С RBAC начинается дичь: либо создается 150 ролей, либо права плывут.
Что любопытно, многие даже не рассматривают ABAC (атрибутный контроль доступа), считая его избыточно сложным. На практике, особенно если у вас уже есть identity propagation через JWT с нормальными scopes, внедрение ABAC не требует героических усилий. В одном из проектов мы пошли по пути гибрида: базовый доступ на ролях, а тонкие настройки — через политики на основе атрибутов (регион, тип документа, сумма транзакции). Работает как часы, и код не раздувается.
mTLS и zero-trust: сказ про сертификаты
Вопрос взаимной TLS-аутентификации между сервисами — это моя любимая мозоль. Сколько раз я видел, как разработчики говорят: «У нас всё внутри кластера, мы всем доверяем». И знаете, это работает ровно до первого инцидента. Один скомпрометированный под — и злоумышленник гуляет по всем сервисам.
Внедрение mTLS — это как проверить проводку в старом доме: тихо, чисто, но если не сделать — рванет. Service mesh вроде Istio сильно упрощает жизнь, но и тут есть нюансы. Например, ротация сертификатов. Если она не автоматизирована, через полгода вы обнаружите, что половина сервисов не работает, потому что сертификаты протухли, а кто их обновлял — никто не помнит.
Личный совет: настраивайте короткоживущие сертификаты и автоматическое обновление. Это снижает риски компрометации, даже если ключ утек, живет он недолго.
Шифрование данных: не только TLS
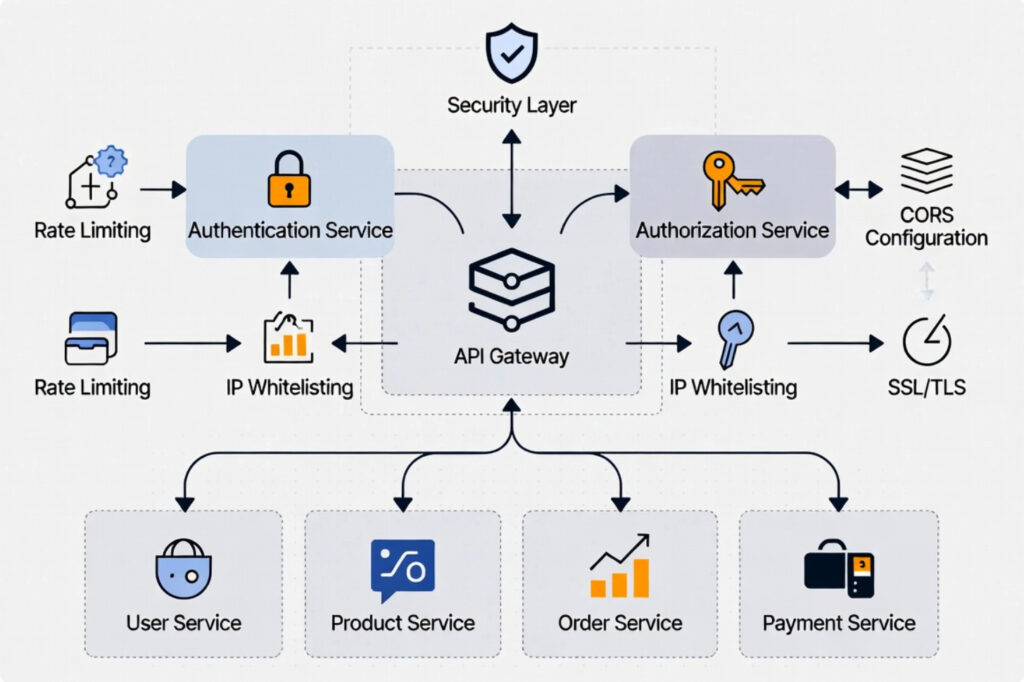
TLS в транзите и at-rest
Обычно все концентрируются на шифровании трафика между сервисами. Это правильно, но недостаточно. Данные в покое (at-rest) тоже должны быть защищены. Причем здесь есть нюанс: если вы используете общее хранилище для логов или S3-совместимое хранилище, шифрование на стороне хранилища — это хорошо, но ключи должны быть вашими.
В одном из аудитов мы обнаружили, что команда шифрует базу, но ключи доступа к хранилищу ключей лежат в открытом виде в репозитории. Это как закрыть дверь на замок, а ключ оставить под ковриком. Сейчас, кстати, многие переходят на field-level encryption, особенно для персональных данных. Это позволяет соответствовать 152-ФЗ, даже если база утекла, злоумышленник получит нечитаемую кашу.
Защита данных в транзите: подводные камни
С шифрованием в транзите тоже не всё гладко. Одно дело — защитить внешний трафик до API gateway. Другое — трафик между микросервисами. Часто внутри кластера Kubernetes шифрование не включают, надеясь на сетевые политики. Но network policies защищают от несанкционированного доступа, а не от перехвата трафика.
Если у вас есть регуляторные требования (PCI DSS, GDPR, 152-ФЗ), шифрование внутри кластера обязательно. И да, mTLS здесь снова в помощь. Но будьте готовы к тому, что производительность просядет процентов на 5–10. Впрочем, современные процессоры с аппаратным ускорением шифрования нивелируют эту разницу.
CI/CD: безопасность как код, а не как галочка
Интеграция security scans в пайплайны
Это, пожалуй, самая болезненная тема для DevOps-команд. С одной стороны, все понимают, что проверять образы на уязвимости нужно. С другой — добавление SAST и DAST в CI/CD часто ломает пайплайны и бесит разработчиков.
По моему опыту, лучший подход — начинать не с блокирующих проверок, а с информирования. Первый месяц просто собираем статистику: какие уязвимости, в каких сервисах, как давно они там. Потом, когда команда привыкает видеть отчёты, можно вводить политики: критичные уязвимости (CVSS 9+) блокируют деплой, высокие — требуют подтверждения от security-чемпиона в команде.
Кстати, про инструменты. Не гонитесь за хайпом. Иногда обычный Trivy в пайплайне и Snyk на этапе сборки дают 90% нужного результата. А всякие сложные корпоративные решения часто пылятся без дела, потому что их никто не умеет настраивать.
Автоматизация compliance
Здесь интересно. Если раньше compliance-проверки были ручными и мучительными, то сейчас их вполне можно автоматизировать. Например, проверка конфигураций на соответствие CIS Benchmarks для Kubernetes или проверка политик сети.
В одном из проектов мы сделали так: каждую ночь запускался скрипт, который проверял все неймспейсы на наличие запрещённых образов, открытых портов и слабых политик. Утром team lead получал отчёт в Telegram. Мелочь, а дисциплинирует.
Угрозы и стандарты: OWASP, NIST и российские реалии
OWASP API Security Top 10 2023 — это база, с которой нужно начинать. Но просто прочитать список недостаточно. Надо понимать, как эти уязвимости проявляются в конкретной архитектуре. Например, «Broken Object Level Authorization» (API1:2023) — это классика. Часто встречается, когда разработчики доверяют ID из запроса, не проверяя, имеет ли пользователь право на этот объект.
SSRF (Server-Side Request Forgery) — еще одна головная боль. Особенно в микросервисах, где один сервис может делать запросы к другому. Если не контролировать, злоумышленник может через уязвимый сервис достучаться до внутренних компонентов.
NIST SP 800-228 и 800-204 дают более системный взгляд на безопасность микросервисов. Там про жизненный цикл, про zero-trust, про шифрование на всех этапах. Но это сложно читать, признаю. Лучше использовать их как чек-лист для аудита.
Для российских компаний важно помнить про 152-ФЗ и приказы ФСТЭК. Если ваше API работает с персональными данными, регуляторы всё чаще проверяют именно защиту API. Были прецеденты, когда штрафовали за отсутствие rate limiting на критичных эндпоинтах, потому что это позволяло злоумышленникам подбирать данные.
Мониторинг и типовые ошибки
Почему мониторинг API — это сложно
С мониторингом микросервисов всегда проблема. Одно дело — мониторить монолит, там понятно: упал — чиним. В распределённой системе запрос может пройти через 10 сервисов, и если один из них ответил медленно, где искать проблему?
Correlation ID — наше всё. Если вы не прокидываете уникальный идентификатор запроса через все сервисы, вы слепы. Без него невозможно собрать трейс запроса и понять, где именно произошёл сбой.
И второе — логи. Они должны быть структурированными (JSON, например) и без персональных данных. Я видел кейсы, когда в логи писали паспортные данные, потому что разработчику было лень их вырезать. При утечке логов — это сразу нарушение 152-ФЗ и большие штрафы.
Типичные ошибки, которые я встречал
Ошибка первая — думать, что безопасность API — это только про gateway. Gateway защищает от внешних атак, но если злоумышленник внутри, он легко обойдёт его, обращаясь напрямую к сервисам. Поэтому защита должна быть эшелонированной: и на gateway, и на каждом сервисе.
Ошибка вторая — забывать про rate limiting. Причём не только на внешнем контуре, но и между сервисами. Один сервис может положить другой просто потому, что начал слать слишком много запросов. Это не злой умысел, а банальная ошибка в коде, но последствия те же — downtime.
Ошибка третья — хардкод секретов. В 2025 году это всё ещё встречается. Пароли в коде, ключи API в конфигах, токены в логах. Используйте секретные менеджеры (HashiCorp Vault, Kubernetes Secrets с шифрованием) и учите разработчиков, что секреты в коде — это табу.
Практические рекомендации и выводы

Если резюмировать всё вышесказанное, безопасность микросервисов и API — это не набор инструментов, а процесс. Нельзя один раз настроить WAF и успокоиться. Угрозы эволюционируют, приложения меняются, и защита должна меняться вместе с ними.
Несколько практических советов, которые реально работают:
Начните с инвентаризации API. Вы удивитесь, сколько эндпоинтов забыто, но работает и доступно извне.
Внедрите минимальные стандарты безопасности в CI/CD. Пусть лучше пайплайн упадёт на этапе сборки, чем в проде.
Используйте service mesh для mTLS и политик, но не включайте всё сразу, тестируйте влияние на производительность.
Регулярно проводите пентесты, хотя бы раз в полгода. Свежий взгляд со стороны находит то, что внутренняя команда уже перестала замечать.
Мы в проектах часто видим, как компании экономят на безопасности на старте, а потом втридорога платят за расследование инцидентов и восстановление репутации. Не повторяйте этих ошибок. Лучше потратить время и ресурсы сейчас, чем потом объяснять клиентам, почему их данные утекли.
Помните, что безопасность — это не враг разработки, а её неотъемлемая часть. Когда разработчики понимают, зачем нужны те или иные проверки, они перестают их саботировать. Рассказывайте, объясняйте, вовлекайте. Тогда результат будет, а не просто галочки в чек-листе.
Нужна помощь с безопасностью ваших API и микросервисов?
Оставьте заявку на бесплатную консультацию на сайте: https://securedefence.ru/
Мы подготовим чек-лист, дорожную карту внедрения защитных мер и коммерческое предложение с учётом специфики вашего бизнеса и требований регуляторов. Для первых 5 заявок в этом месяце — расширенный аудит безопасности API в подарок.
Часто задаваемые вопросы
Вопрос: Мы только начинаем переход на микросервисы. С чего вообще начинать безопасность, чтобы не перегрузить команду и не остановить разработку?
Если честно, самая частая ошибка на старте — пытаться объять необъятное и внедрить всё и сразу: и service mesh, и сложные политики, и сканеры во все пайплайны. В результате разработка встаёт колом, а безопасность объявляют врагом народа.
По опыту, начинать нужно с трёх базовых вещей, которые дадут 80% защиты при 20% усилий. Первое — инвентаризация. Вы удивитесь, но часто архитекторы не знают полного списка своих API. Просто пройдитесь по коду, соберите все эндпоинты, посмотрите, что из этого смотрит наружу. Второе — базовая гигиена аутентификации. JWT с нормальными scopes и проверка, что пользователь имеет право на объект (это как раз та самая Broken Object Level Authorization, через которую происходит большинство утечек). Третье — rate limiting на внешнем контуре. Это спасёт от случайных DDoS и глупых ошибок интеграций. Всё остальное можно достраивать постепенно, когда команда созреет.
Вопрос: Мы используем Kubernetes. Достаточно ли сетевых политик (NetworkPolicy) для защиты трафика между сервисами, или mTLS всё же обязательно нужен?
Отличный вопрос. Сетевые политики и mTLS решают разные задачи, хотя многие их путают. NetworkPolicy — это про доступ на уровне сети: кто имеет право соединяться с кем. Это как пропускной режим в здании: вы не пустите постороннего в серверную. Но если внутри здания есть прослушка, все разговоры будут слышны.
mTLS добавляет шифрование и взаимную аутентификацию. Даже если злоумышленник каким-то образом попал внутрь кластера и может слать пакеты, без правильного сертификата он не сможет представиться легитимным сервисом и расшифровать трафик. Поэтому мой ответ: если ваши данные не представляют ценности и не подпадают под регуляторику, можно ограничиться NetworkPolicy. Если есть риск утечки или требования compliance (152-ФЗ, GDPR), mTLS обязателен. В современных service mesh это не так сложно настроить, как кажется.
Вопрос: Как часто нужно проводить пентесты API и микросервисов? Раз в год достаточно?
(лёгкая усмешка) Знаете, я часто слышу этот вопрос. Формально, многие стандарты требуют раз в год. Но на практике… Представьте, что вы меняете замки в квартире раз в год, а воры приходят каждый день. Звучит глупо, правда?
Ситуация с API меняется гораздо быстрее, чем с монолитными приложениями. Вы могли за неделю выкатить десять новых микросервисов и забыть про них. Поэтому я рекомендую другой подход: continuous security testing. Это не значит, что хакеры должны жить у вас в офисе. Это значит, что базовые автоматизированные сканеры должны быть встроены в CI/CD и работать на каждый коммит. А полноценный ручной пентест с анализом бизнес-логики — делать хотя бы раз в полгода или после серьёзных изменений архитектуры.
Вопрос: У нас legacy-монолит, который мы постепенно режем на микросервисы. Как не потерять безопасность в процессе этой миграции?
О, это классическая боль. Когда режете монолит, часто получается лоскутное одеяло: часть логики аутентификации осталась в старом монолите, часть вынесли в новый сервис, и в итоге дырок — хоть отбавляй.
Мой главный совет: не размазывайте безопасность тонким слоем. Сделайте единый контур аутентификации и авторизации (например, отдельный сервис или API gateway) как можно раньше. Все новые микросервисы должны стучаться к нему за проверкой прав. А старый монолит пока живёт по старым правилам, но вы его постепенно отключаете. И обязательно логируйте всё, что проходит через этот «пограничный» сервис. Когда начнутся проблемы (а они начнутся), вы сможете быстро понять, где именно сломалось.
Вопрос: Что делать, если разработчики сопротивляются внедрению, считают, что это тормозит разработку?
Тут нужна не дубина, а дипломатия. Обычно сопротивление идёт от непонимания. Если разработчику сказать: «Ты должен прогонять свой код через SAST, иначе не покатит», он воспримет это как наказание. Если же объяснить: «Смотри, этот сканер ловит 80% глупых ошибок, которые потом на пентесте найдут и заставят переделывать, и мы сэкономим неделю времени на переписывании кода», — отношение меняется.
По моему опыту, лучше всего работает внедрение безопасности как self-service. Разработчики любят, когда у них есть выбор и инструменты, а не когда кто-то сверху спускает директивы. Сделайте понятный портал с документацией, чек-листами, примерами кода. Пусть они сами приходят за помощью, когда видят в этом ценность. И, кстати, не забывайте хвалить команды, которые делают безопасно. Публичные доски почёта работают лучше любых штрафов.
Вопрос: На какие метрики смотреть, чтобы понять, что безопасность API действительно работает, а не просто существует?
Метрики — это больная тема. Количество найденных уязвимостей — плохая метрика, потому что если сканеры настроены зря, они могут показывать ноль, а безопасность при этом никакая.
Я бы смотрел на три вещи. Первое — время реакции (MTTR) на инциденты безопасности. Если что-то случилось с API, сколько времени уходит на детект и локализацию? Correlation ID и структурированные логи должны сокращать это время до минут. Второе — процент покрытия критичных сервисов автоматическими проверками в CI/CD. Если у вас 50 микросервисов, а проверяются только 10, это повод задуматься. Третье — количество инцидентов, связанных с человеческими ошибками (например, забыли закрыть доступ к эндпоинту). Это показатель зрелости процессов. Если такие инциденты стремятся к нулю, значит, автоматизация и культура работают.
Вопрос: Есть ли какие-то специфические требования к безопасности API в российских компаниях, помимо 152-ФЗ?
Да, и их становится всё больше. Кроме 152-ФЗ, сейчас активно набирает обороты приказ ФСТЭК №31 (о защите значимых объектов КИИ). Если ваша компания попадает под КИИ, требования к защите каналов связи и к самому API ужесточаются. Нужно использовать сертифицированные СКЗИ (средства криптографической защиты информации) для передачи данных. Просто TLS уже может быть недостаточно — нужен ГОСТ-шифрование.
Также Центробанк активно интересуется безопасностью API в финансовом секторе. У них есть свои стандарты (СТО БР ИББС), где про API написано достаточно много, особенно про открытые API (Open Banking). Там требования к логированию, к защите от несанкционированного доступа очень жёсткие. Так что просто следовать мировым best practices уже не получится, надо смотреть на локального регулятора.
══════
Оставьте заявку на бесплатную консультацию: [Перейти на сайт]